概率论基础
概率论在统计分析中扮演着至关重要的角色。它不仅为统计分析提供了理论基础,还在实际应用中发挥着重要作用。概率论帮助我们理解和量化数据中的随机性和变异性。统计分析中经常使用各种概率分布(如正态分布、二项分布、泊松分布等)来描述数据的行为。这些分布是概率论的直接产物,并且在数据分析中非常重要。
概率论的基本概念
随机现象
在一定的条件下,并不总是出现相同结果的现象称为随机现象。自然界和社会上发生的现象中,有一类现象,在观察之前不能预知确切的结果,但是这类现象在大量重复观察下,它的结果具有统计规律性。
随机现象具有如下特点:
- 结果不止1个;
- 哪个结果出现,人们事先并不知道。
随机试验
具有以下三个特点的试验为随机试验:
- 可以在相同的条件下重复进行;
- 每次试验的可能结果不止一个,并且能事先明确试验的所有可能结果;
- 试验在进行之前不能确定结果。
样本空间
随机试验\(E\)的所有可能结果组成的集合成为\(E\)的样本空间,记为\(S\)。样本空间的元素,即\(E\)的每个结果,称为样本点。
随机事件
随机事件指的是试验\(E\)的样本空间\(S\)的子集,简称事件。在每次试验中,当且仅当这一子集中的一个样本点出现时,称这一事件发生。
频率与概率
在相同的条件下,进行了\(n\)次试验,在这\(n\)次试验中,事件\(A\)发生的次数\(n_A\)称为\(A\)发生的频数。比值\(n_A/n\)称为事件\(A\)发生的频率,记作\(f_n(A)\)。
设\(E\)是随机试验,\(S\)是它的样本空间。对于\(E\)的每一事件\(A\)赋予一个实数,记作\(P(A)\),称为事件\(A\)的概率。概率是事件的函数。
当\(n\)趋向于无穷大时,\(f_n(A)\)接近于概率\(P(A)\)。基于这一事实,我们就有理由将概率\(P(A)\)用来表征事件\(A\)在一次试验中发生的可能性。
实际推断原理
人们在长期的实践中总结得到,概率很小的事件(也叫小概率事件)在一次试验中实际上几乎是不发生的。如果概率很小的事件在一次试验中发生了,就有理由怀疑假设的正确性。
小概率事件
通常习惯上把 \(P≤0.05\) 或 \(P≤0.01\) 的事件称为小概率事件。除特别注明以外,小概率事件一般是指 \(P≤0.05\) 的事件。
由于小概率事件的概率较小,发生的可能性不是太大,甚至接近于0,所以在日常生活中普遍认为“在1次试验中小概率事件实际上是不可能发生的”,被称为小概率事件实际不可能发生原理。
严格意义上讲,它是人们在长期实践中总结出的一条统计学公理,是把\(P= 0.05\)或\(P=0.01\)作为差异是否具有统计学意义的界值依据,是统计学假设检验拒绝或不拒绝原假设\(H_0\)的判断准则。
大数定律
随着\(n\)的增加,事件\(A\)发生的频率\(\frac{f_A}{n}\)与其概率\(p\)的偏差大于预先给定的精度\(\varepsilon\)的可能性越来越小,要多小有多小,即频率稳定于概率。
\[\lim _{n \rightarrow \infty} P\left\{\left|\frac{f_{A}}{n}-p\right| \geqslant \varepsilon\right\}=0\]
伯努利大数定理表明,只要重复独立实验的次数n重复大,事件\(\{|\frac{f_A}{n}-p|\geqslant\epsilon\}\)是一个小概率事件,由实际推断原理知,这一事件实际上几乎是不发生的。
当试验次数很大时,可以用事件的频率来代替事件的概率。比如,我们向上抛一枚硬币,硬币落下后哪一面朝上是偶然的,但当我们上抛硬币的次数足够多后,达到上万次甚至几十万几百万次以后,我们就会发现,硬币每一面向上的次数约占总次数的二分之一,亦即偶然之中包含着必然。
条件概率
设\(A\),\(B\)是两个事件,且\(P(A)>0\),称\(P(B|A)=\frac{P(AB)}{P(A)}\)为在事件\(A\)发生的条件下事件\(B\)发生的条件概率。
事件的相互独立
事件相互独立的含义是事件中的一个已发生,不影响另一个事件发生的概率。如果事件之间没有关联或者关联很弱,就认为它们是相互独立的。例如:相距很远的两个人患感冒。
随机变量及其分布
随机变量
用来表示随机现象结果的变量称为随机变量。随机变量的取值随试验的结果而定,在试验之前不能预知它的值。例如:某课程某一天的缺勤人数,某一天的降雨量,某一个视频的观看人数等等。
设随机试验的样本空间为\(S=\{e\}\),\(X=X(e)\)是定义在样本空间\(S\)上的实值单值函数。称\(X=X(e)\)为随机变量。通常使用大写字母\(X\),\(Y\),\(Z\),\(W\)等表示随机变量。
任意随机变量都有一个分布函数。有了分布函数,就可据此计算随机变量有关事件的概率。
假设一个随机变量仅可能取有限个或可列个数,则称其为离散型随机变量。如果一个随机变量的可能取值充满数轴上的一个区间,则称其为连续型随机变量。
离散型随机变量及其分布律
有些随机变量,它全部可能取到的值是有限多个,或者可列无限对个,这种随机变量称为离散型随机变量。例如,某一天出生的新生儿,某一个企业的产品类别,某一天接到的电话数量等等。
离散型随机变量的分布律
离散型随机变量的分布,按照其取值的数量有着不同的分布:
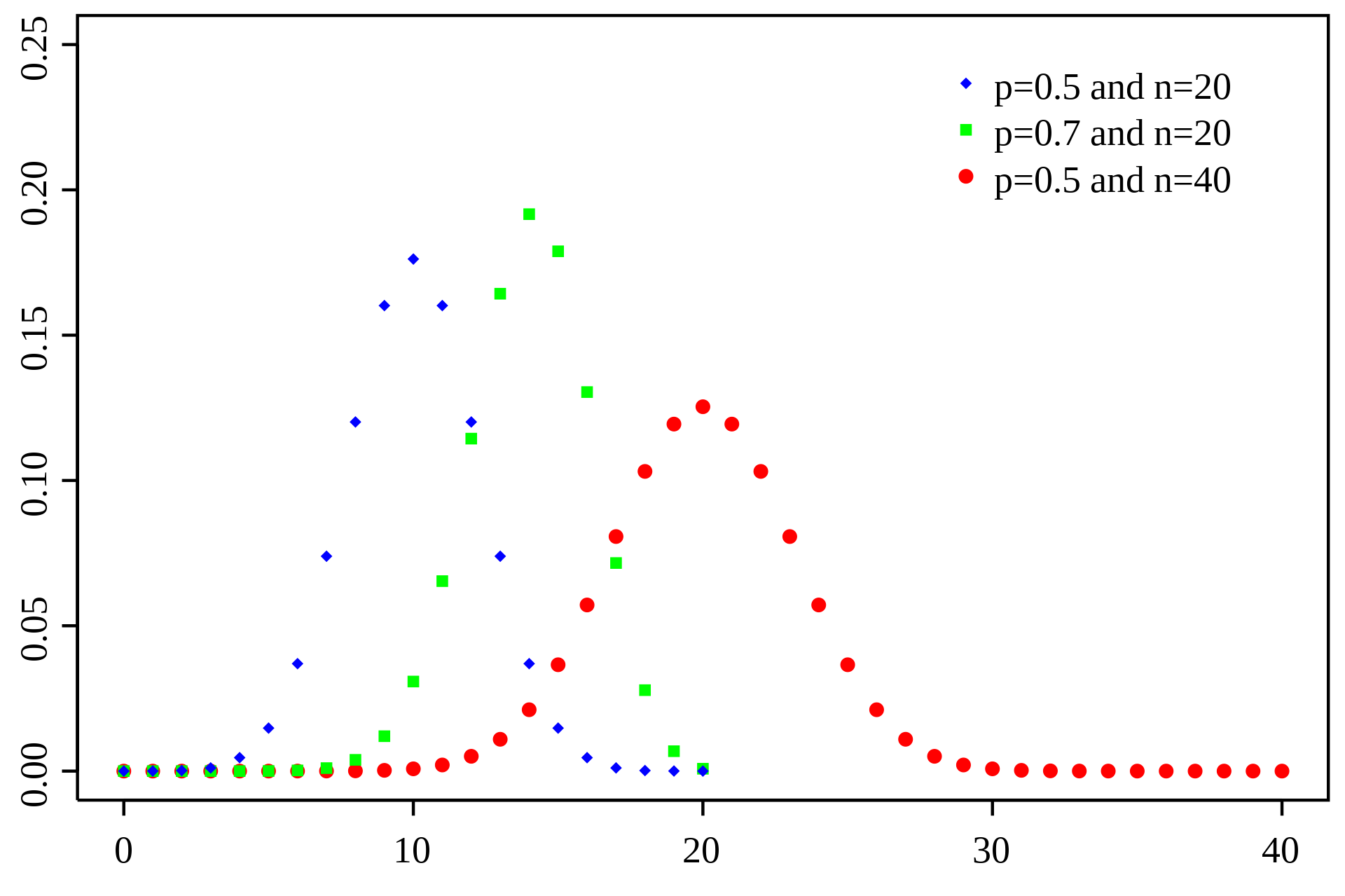
二项分布
所谓二项,是指变量只有两个值。类别变量的值,可视为二项。在概率论和统计学里面,带有参数n和p的二项分布表示的是n次独立试验的成功次数的概率分布。在每次独立试验中只有取两个值,表示成功的值的概率为p,那么表示试验不成功的概率为1-p。这样一种判断成功和失败的二值试验又叫做伯努利试验。特殊地,当n=1的时候,我们把二项分布称为伯努利分布。
计算公式:
\[p(r)=\dfrac{n!}{r!(n-r)!}P^rQ^{n-r}\]
- n:样本规模
- r:成功的数目
- P:每次的成功机会
- Q:每次的失败机会
- p(r):获得r次成功个案的概率
如果n=3,则在三个个案中有一次成功的概率为:
\[p(1)=\dfrac{3!}{1!(3-1)!}0.5^10.5^{3-1}=\frac{3}{8}\]
二项分布的特点
- 当样本规模很大时,二项抽样分布(P=Q)可以近似为正态分布。当P不等于Q时(P+Q=1),抽样分布是不对称的,但是依然可以计算具体情况出现的概率。
- 随着抽样次数k的增加,概率先随之增加,到达最大值后单调减少。

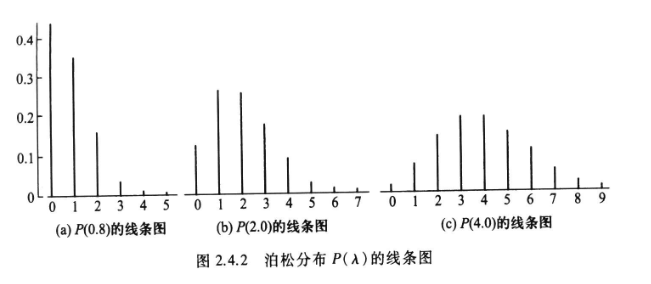
泊松分布
设随机变量X所有可能取的值为0,1,2,…,而取各个值的概率为:
\[p\{x=k\}=\frac{\lambda^ke^{-\lambda}}{k!},k=0,1,2,…\]
其中 \(\lambda >0\) 是常数,则称\(X\)服从参数为\(\lambda\)的泊松分布。记作\(X\sim\pi(\lambda)\)。

泊松分布的特点
- 位于均值\(\lambda\)附近的概率较大。
- 随着 \(\lambda\) 的增大,分布逐渐趋于对称。
连续型随机变量及其分布
连续型随机变量指取值连续,不能一一列举出来的随机变量。例如灯泡的寿命,某个职业的收入。连续型随机变量的取值可以是小数。
连续型随机变量的概率密度函数
对于随机变量\(X\)的分布函数\(F(x)\),存在非负函数\(f(x)\),对于任意实数\(x\)有
\[F(x)=\int_{-\infty}^{x}f(t)dt\]
则称\(X\)为连续型随机变量,其中函数\(f(x)\)为\(X\)的[[概率密度函数]],简称概率密度。

连续型随机变量的分布
均匀分布

例如:电阻值
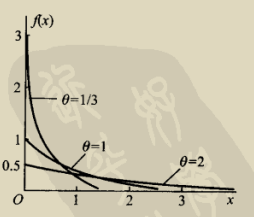
指数分布
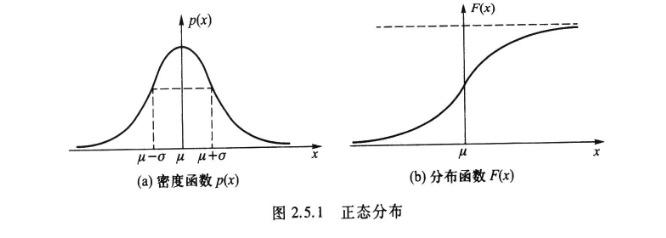
正态分布

大量随机变量都服从或近似服从正态分布。如身高、成绩、视力等等。
数学定义
若随机变量\(X\)的概率密度函数为
\[p(x)=\frac{1}{\sqrt{2\pi}\sigma}^{-\frac{(x-\mu)^2}{2\sigma^2}}\]
则称\(X\)服从正态分布,称\(X\)为正态变量。
正态分布的密度函数及分布函数
标准正态分布
u=0,\(\sigma\)=1时的正态分布为标准正态分布。

在实际应用中,任何正态分布都可以通过标准化(减去均值后除以标准差)转换成标准正态分布。这使得标准正态分布表或相关软件工具可以用于各种不同的正态分布。
“68-95-99.7”规则
在标准正态分布中,大约68%的值落在距均值1个标准差以内(即在-1和1之间),95%的值落在距均值2个标准差以内(即在-2和2之间),而99.7%的值落在距均值3个标准差以内(即在-3和3之间)。
标准正态分布在许多领域中都有广泛应用,包括社会科学、自然科学、工程学等。它不仅是理解和应用其他正态分布的基础,也是许多统计方法和测试的核心。
抽样分布
抽样分布是指,当从同一总体中重复抽取大小相等的样本时,某个统计量的所有可能值的分布。抽样分布是统计学中的一个核心概念,它描述了从总体中抽取样本时,某个统计量(如样本均值、样本比例等)的概率分布。这个概念在进行统计推断时特别重要,因为它帮助我们理解和量化从样本数据推断总体参数时的不确定性。
- 样本均值的抽样分布:最常见的抽样分布之一,特别是当样本量较大时,由于中心极限定理,样本均值的分布通常接近正态分布。
- 样本比例的抽样分布:用于比例数据,例如二项分布的样本比例。
抽样分布使我们能够评估从样本中得到的统计量与总体参数之间的差异,它提供了从样本数据推断总体特征时所需的理论基础,为构建置信区间和执行假设检验提供了理论依据。通过理解抽样分布,统计学家和研究人员能够更准确地评估他们的推断结果的可靠性。
置信区间与置信水平
置信区间(Confidence interval)是一种用来表示估计值不确定性的区间估计。它给出了一个范围,我们相信这个范围内包含了某个未知的总体参数(如均值、比例等)的真实值。置信水平是与置信区间相联系的一个概念,它表示置信区间包含总体参数真实值的可信程度,通常以百分比表示,如95%置信水平。
假设你要估计一个班级学生的平均身高。你可能会说:“我相信这个班级学生的平均身高在1.6米到1.7米之间。”这里的“1.6米到1.7米”就是一个置信区间。它表明你相信真正的平均身高会落在这个区间内。但是,这个估计并不是绝对准确的,它有一个可能的误差范围。如果你说这个估计(1.6米到1.7米)是基于95%的置信水平,这就好比说:“如果我们用同样的方法多次估计班级平均身高,那么大约有95%的情况下,这个班级的真实平均身高会落在我们计算出的置信区间内。”换句话说,置信水平给出了你对这个估计区间准确性的信心程度。
将置信区间和置信水平结合起来看,它们提供了一种量化估计结果不确定性的方法。高置信水平意味着更大的信心,但通常也会导致更宽的置信区间,反映了较高的不确定性。在实际应用中,这两个概念帮助我们理解和解释数据,同时也提示我们任何基于样本数据的估计都存在一定的不确定性。
置信区间的计算公式
置信区间的计算公式取决于估计的参数(如均值、比例等),样本的大小,以及数据是否符合某些分布(如正态分布)。以下是几种常见情况下置信区间的计算公式:
均值的置信区间(总体方差已知)
当总体方差已知时,均值的置信区间可以使用以下公式计算:
\[\bar{x} \pm z \times \frac{\sigma}{\sqrt{n}}\]
其中:
- \(\bar{x}\) 是样本均值。
- \(z\) 是标准正态分布的z分数(例如,对于95%置信水平,\(z\)约等于1.96)。
- \(\sigma\) 是总体标准差。
- \(n\) 是样本大小。
均值的置信区间(总体方差未知)
当总体方差未知且样本量较小时,使用t分布:
\[\bar{x} \pm t \times \frac{s}{\sqrt{n}}\]
其中:
- \(\bar{x}\) 是样本均值。
- \(t\) 是t分布的t分数,依赖于置信水平和自由度(自由度一般为 \(n - 1\))。
- \(s\) 是样本标准差。
- \(n\) 是样本大小。
比例的置信区间
对于比例的置信区间,公式为:
\[\hat{p} \pm z \times \sqrt{\frac{\hat{p}(1-\hat{p})}{n}}\]
其中:
- \(\hat{p}\) 是样本比例。
- \(z\) 是标准正态分布的z分数。
- \(n\) 是样本大小。
随机变量的数字特征
随机变量的数字特征是用来描述其统计属性的一组重要指标。这些特征能够概括随机变量的分布和行为。主要的数字特征包括:
数学期望
级数\(\sum_{k=1}^{\infty}x_kp_k\)的和为离散型随机变量X的数学期望。如掷骰子的时候,出现1点的期望为1/6。对于离散型的随机变量\(X\)的数学期望,它只与\(X\)可能的取值及每个取值的概率有关,即只与\(X\)的分布有关系。
连续型随机变量的期望值就是均值。
方差和标准差
方差衡量了随机变量取值与其期望值的偏离程度,是随机变量波动性的度量。方差是随机变量与其均值之差的平方的期望值。标准差是方差的平方根,具有与原随机变量相同的量纲,更便于解读。
协方差和相关系数
当考虑两个随机变量时,协方差描述了这两个变量之间的线性关联程度。正协方差表示正相关,负协方差表示负相关。相关系数是协方差除以两个随机变量的标准差,用于度量变量间的相关强度。
关于协方差的讲解,可以参看视频:https://www.zhihu.com/zvideo/1520790246182969344。
偏度(Skewness)
偏度是描述随机变量概率分布不对称性的度量。正偏度表示分布的尾部更偏向于右侧,负偏度表示更偏向于左侧。
峰度(Kurtosis)
峰度是描述随机变量概率分布尖锐程度的指标。高峰度表明分布具有尖锐的峰和厚重的尾部,低峰度则表明分布较为平坦。
参考文献
- 陈正昌, 贾俊平. (2016). 统计分析与R. 中国人民大学出版社.
- 贾俊平. (2021). 统计学——Python实现. 高等教育出版社.
- 李沛良. (2001). 社会研究的统计应用. 社会科学文献出版社.
- 张文彤. (2017). SPSS统计分析基础教程(第3版). 高等教育出版社.