Pandas是一个开源的Python库,广泛应用于数据分析和处理领域。自2008年由Wes McKinney开发以来,它已成为Python数据分析中不可或缺的工具,尤其在金融、科学、工程和学术研究等行业中备受青睐。Pandas的核心是提供了两种高效的数据结构:DataFrame和Series。DataFrame是一种二维表格结构,可以存储和操作异构数据,类似于Excel电子表格中的工作表。而Series则是一种一维数组,用于存储单一类型的数据列。
Pandas的主要优势在于其能够轻松处理和分析大型数据集。它支持各种文件格式的数据导入和导出,包括常见的CSV、Excel和JSON等。Pandas的数据处理功能强大而全面,从基本的数据清洗(如处理缺失值、过滤数据)、数据转换(如分组、合并、重塑和排序)到复杂的聚合操作,都能轻松应对。
在数据分析的工作流中,Pandas通常与其他Python库如NumPy、Matplotlib和SciPy紧密集成,提供了一个强大的数据分析环境。同时,它也与各种机器学习库兼容良好,特别是与Scikit-Learn结合,常用于机器学习项目中的数据预处理阶段。
简而言之,Pandas以其强大的功能和灵活性,成为了处理和分析表格数据的首选工具。无论是数据科学家、研究人员还是工程师,都可以依赖Pandas来高效地完成数据处理和分析任务。
两种数据结构:Series和DataFrame
Pandas 是 Python 中用于数据分析的重要库,其核心功能是提供了两种高效的数据结构:Series 和 DataFrame。这两种结构为处理大量数据提供了极大的便利,使得数据操作更加直观和方便。
Series
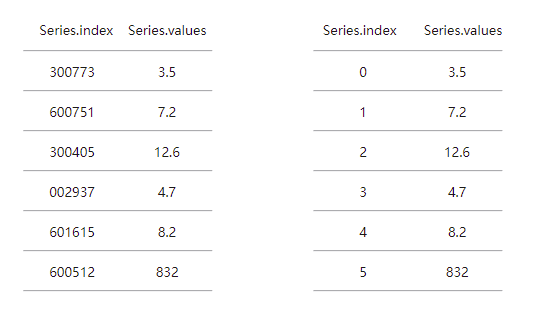
Series 是 Pandas 中的一种一维数组结构,可以被看作是一个固定长度、有序的字典。每个 Series 对象都由两个主要组成部分构成:
- 值(Values):一个包含存储在 Series 中的数据值的数组。这些值可以是任何数据类型,如整数、浮点数、字符串等。
- 索引(Index):与值相关联的标签序列,用于快速访问和操作数据。默认情况下,索引是从 0 开始的整数序列,但也可以自定义为其他类型,如字符串或日期。
Series 的用途非常广泛,可以用来表示时间序列、表格中的单列数据等。它支持各种操作,包括算术运算、聚合、数据对齐以及复杂的索引操作。
DataFrame
DataFrame 是 Pandas 中的另一个核心数据结构,是一种二维的、表格型的数据结构。DataFrame 可以被看作是多个 Series 对象的集合,其中每个 Series 作为 DataFrame 的一列。DataFrame 的每列可以包含不同类型的数据(数值型、字符串型、布尔型等),这与现实生活中的电子表格或 SQL 表格类似。DataFrame 的两个主要组成部分是:
- 数据(Data):存储在多个列中的数据。每列都像一个 Series,可以是不同的数据类型。
- 索引(Index):与 Series 类似,DataFrame 也有索引,用于快速定位数据和进行各种操作。DataFrame 不仅在行上有索引,还在列上有标签,使得对数据的访问和操作更加方便。
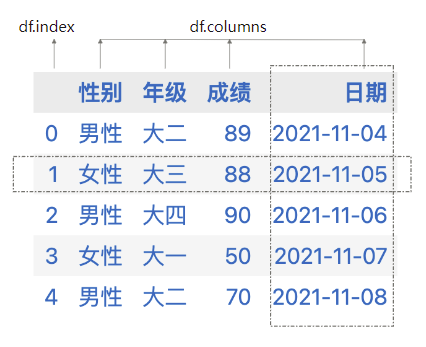
在数据框(dataframe)中,通常情况下,列表示变量(variable),行表示案例(case),有多少行数据,就表示多少个案例。上图所示的dataframe中,有性别、年级、成绩、日期四个变量。这些变量位于列中,而一行数据就表示一个具体的案例,如第一行数据就表示某个大二的男性,成绩为89,对应日期为2021-11-04。
虽然DataFrame中行和列可以非常方便的进行转换,但我们建议使用行表示案例,使用列表示变量,这样与多数人的认知保持一致,也与诸如SPSS之类的分析工具中的数据组织方式保持一致。
DataFrame 适合用于处理实际工作中常见的各种数据形式,如电子表格、SQL表数据、时间序列数据等。它支持各种数据操作,包括数据过滤、排序、分组、合并等。
读取和保存数据
读取和保存数据在数据分析过程中非常重要,因为它们是数据分析工作流的关键环节,对整个分析过程的效率和结果有着决定性的影响。读取数据是获取数据的第一步,而数据是进行任何分析的基础。无法有效读取数据意味着无法开始分析工作。数据可能存储在不同的格式和来源中,例如CSV、Excel文件、数据库或网上的API。能够从这些多样化的来源中读取数据是灵活处理和分析数据的关键。有效的数据读取方法可以显著提高数据处理的速度,尤其是在处理大量数据时。自动化和优化数据读取流程可以节省大量时间。在数据读取阶段,可以早期发现数据的问题,如格式错误、缺失值或不一致性,这对于随后的数据清洗和准备工作至关重要。
读取CSV格式数据
CSV是Comma-Separated Values的缩写,直译为逗号分隔值,这种格式的文件以纯文本形式存储表格数据(数字和文本)。CSV文件多以逗号为字段之间的分隔符,但也可以使用其他的字符作为字段之间的分隔符。例如:1997,Ford,E350,"ac, abs, moon",3000.00就是一行CSV格式的数据。CSV因其格式简单,且为纯文本,故被广泛采用在不同数据处理工具中。在线调查网站、Excle、WPS、SPSS、Python、R等等不同工具,都支持CSV格式数据的导入导出。
Pandas包中提供了pandas.read_csv方法读取CSV文件,读取成功后,该方法返回DataFrame类型的数据。例如:pd.read_csv('data.csv')。
read_csv方法的常用参数:
encoding,指定unicode的文本编码格式。sep或delimiter,用于设定文件分隔符。header,用作列名的行号,默认为0,csv文件中没有表头时需要将header设为None。index_col,用作行索引的列编号。names,自定义的列名列表,结合header=None。skiprows,需要跳过读取的行数(从文件开始计算),或需要跳过的行号列表(从0开始)。nrows,仅读取开始的若干行。
import pandas as pd
fileUrl = r"../../data/csv/600519.csv"
df1 = pd.read_csv(fileUrl, encoding="utf-8")
df1.head(3)
| 0 |
2001/8/27 |
6005191 |
34.51 |
35.55 |
37.78 |
32.85 |
406318 |
1410347008 |
| 1 |
2001/8/28 |
6005191 |
34.99 |
36.86 |
37.00 |
34.61 |
129647 |
463463008 |
| 2 |
2001/8/28 |
6005191 |
34.99 |
36.86 |
37.00 |
34.61 |
129647 |
463463008 |
# 读取在线csv文件
fileUrl = r"https://oss-yangjh.oss-cn-chengdu.aliyuncs.com/data/csv/600519.csv"
df2 = pd.read_csv(fileUrl)
df2.head(3)
| 0 |
2001-08-27 |
6005191 |
34.51 |
35.55 |
37.78 |
32.85 |
406318 |
1410347008 |
| 1 |
2001-08-28 |
6005191 |
34.99 |
36.86 |
37.00 |
34.61 |
129647 |
463463008 |
| 2 |
2001-08-29 |
6005191 |
36.98 |
36.38 |
37.00 |
36.10 |
53252 |
194689000 |
pandas.read_csv方法的filepath_or_buffer参数可以是字符串形式的本地文件地址,还可以是URL。例如:pd.read_csv('https://oss-yangjh.oss-cn-chengdu.aliyuncs.com/data/csv/600519.csv')将读取在线的数据。
需要注意的是,以URL形式提供的数据地址,必须是可以公开访问的,否则会出现权限错误。
读取xls格式的数据
除了CSV格式的数据外,常用的数据格式还有xls、xlsx等MS Excel支持的格式。使用Pandas提供的read_excel()方法,可以读取xls及xlsx的数据。不过在使用该方法前还需要安装openpyxl包。
read_excel方法的常用参数:
filepath,文件路径名,要求是字符串类型。sheet_name,excel文件中的工作表,默认为第一个工作表。
file_url = r'../../data/xls/招聘信息v2.xlsx'
df_jobs = pd.read_excel(file_url)
df_jobs.head(2)
| 0 |
彬煌投资贸易 |
5k-8k·13薪 |
大数据分析助理 |
深圳 |
经验不限 |
大专及以上 |
全职 |
| 电商 | 分类信息 | |
16:12 |
五险一金 年底双薪 包住 全勤奖 带薪年假 |
NaN |
深圳-罗湖区-笋岗 |
2020-09-07 21:11:55 |
| 1 |
快手 |
20k-40k |
(大数据专场)Java后端研发... |
北京 |
经验3-5年 |
本科及以上 |
全职 |
| |
17:53 |
大牛多 |
NaN |
北京-海淀区-西二旗-上地西路6号快手总部 |
2020-09-07 21:12:01 |
读取SPSS格式数据
SPSS 是一款用户众多的商业统计分析工具,该工具的数据默认以sav格式保存,对于sav格式的数据,我们可以通过SPSS 提供的导出功能,将其保存为csv或者xls格式。也可以使用Python直接打开sav格式的数据。建议使用Python直接打开。
使用Pandas的read_spss方法
Pandas的read_spss方法可以读取sav格式的数据文件。主要参数如下:
path : str or Path 文件路径及名称;usecols : list-like, optional 指定读取的列,如果该参数没有值,则读取全部变量。convert_categoricals : bool, 默认为真,决定是否将SPSS中的类别变量转化为Pandas中的类别变量。
该方法不够灵活,建议使用更为灵活的pyreadstat.read_sav()方法。
使用 pyreadstat 的 read_sav 方法
Pandas使用第三方包pyreadstat包对流行的商业统计分析软件的数据文件进行读写。故需安装pyreadstat。例如pip install pyreadstat,对于没有管理员权限的用户,运行pip install -U pyreadstat。
导入pyreadstat包后,使用pyreadstat提供的pyreadstat.read_sav方法可以读取sav格式的数据文件。该函数的返回值是元组,第一个元素为DataFrame类型的数据,第二个元素为整个表变量的定义信息。
pyreadstat.read_sav函数参数说明:
apply_value_formats 默认为False,如果我们想要标签描述(即变量中的选项名称,如喜欢、不喜欢),而不仅仅是数字的话(即变量在SPSS中的数值,通常为1、2……),需要将这个参数设置为True。formats_as_category 默认为True, 意味着读入到Pandas时会将变量转化为category类型的列。formats_as_ordered_category 默认为False,需要将其设置为True,这样pandas在读取时,会保留在SPSS中定义的变量测量层次。
全部函数参数可到 pyreadstat documentation 查询。
from pyreadstat import pyreadstat
# 打开sav格式数据的时候,保留标签值、保留变量测量层次设定。
df, metadata = pyreadstat.read_sav(
R'../../data/sav/identity.sav', formats_as_ordered_category=True, apply_value_formats=True)
df['年级']
0 大四
1 大四
2 大四
3 大四
4 大四
..
900 大一
901 大三
902 大二
903 大一
904 大四
Name: 年级, Length: 905, dtype: category
Categories (5, object): ['预科' < '大一' < '大二' < '大三' < '大四']
读取PDF中的表格数据
有些时候,我们所需要的数据是以PDF中的表格形式存在的,借助于第三方包pdfplumber,可以非常方便地读取pdf中的表格数据。
首先,需要安装pdfplumber:
读取pdf中表格数据的流程
- 获取全部pdf页数;
- 通过循环逐页读取当前页面中的表格;
- 将表格转化为Pandas中的
DataFrame。
例如:
import pdfplumber
import pandas as pd
pdf = pdfplumber.open(R'../../data/pdf/高考核心词汇1278.pdf')
table = []
# len(pdf.pages)获取全部pdf页数;
for i in range(len(pdf.pages) - 1):
# 通过循环逐页读取当前页面中的表格;
page = pdf.pages[i + 1]
table.extend(page.extract_table())
# 将表格转化为Pandas中的`DataFrame`。
table1_df = pd.DataFrame(table[2:])
table1_df.head(2)
| 0 |
1 |
None |
a(an) |
[ə] 、 [ən] |
art. 一(个,件) |
An hour ago, a European bought an \nMP3. |
1 小时前,一位欧洲人买了一个 MP3。 |
None |
| 1 |
2 |
None |
abandon |
[əˈbændən] |
vt.放弃,抛弃; |
He abandoned his wife and children \nand went ... |
他抛妻弃子,并带走了所有的钱。 |
None |
将DataFrame保存为不同格式的外部数据文件
将一个 DataFrame 保存为不同格式的外部数据文件,如 CSV、Excel 和 SPSS 的 .sav 格式,通常需要使用不同的 Python 库。下面是如何实现这一点的简要概述:
保存为CSV格式文件
使用 pandas 库中的 to_csv() 方法可以轻松地将 DataFrame 保存为 CSV 文件。
保存为Excel格式文件
使用 pandas 的 to_excel() 方法,可以将 DataFrame 保存为 Excel 文件。
保存为SPSS格式文件
将 DataFrame 保存为 SPSS 文件稍微复杂一些,通常需要将标签值,转化为数字,再写入sav,保留变量定义时的标签值、测量层次等重要信息。这样才能充分利用sav格式的优势。
例如:
# 将标签值,转化为数字,再写入sav,保留变量定义时的标签值、测量层次等重要信息
pyreadstat.write_sav(df2,
'spss格式数据演示.sav',
variable_value_labels=metadata.variable_value_labels,
variable_measure=metadata.variable_measure,
variable_format=metadata.original_variable_types)
Pandas中的索引
所谓索引(indexing),就是按照某种特征对数据进行排序和查找,DataFrame 的索引有行索引index和列索引columns。
使用DataFrame索引的基本方式
- 使用
[]可以获取某一列,或者某几列的数据。例如如df2['close']或df2[['close','open']],其中close、open为列标签。
- 使用
.可以获取某一列的数据。如df2.close。
DataFrame中的三种索引方式
- 使用标签索引loc。标签既可以是行标签,也可以是列标签。
- 使用整数位置索引iloc。如第几行第几列。
- 使用函数索引。符合一定条件的回调函数可作为
loc、iloc以及[]方式的索引器值。
行索引
DataFrame的行索引为index。使用index.values可以得到全部行索引的值。如果没有特别指定索引,默认的行索引值为从0开始的整数。
gzmt = pd.read_csv(R'../../data/csv/600519.csv')
gzmt.index.values
array([ 0, 1, 2, ..., 4092, 4093, 4094], dtype=int64)
当索引值为默认的递增整数时,其数值除了具有唯一性外,对分析人员而言,其并不具有额外的信息。多数情况下,在进行数据分析时,我们会设置更有识别性的变量作为行索引,如日期、学号等等。使用set_index方法 ,可将 dataframe 其中某列的值作为行索引。使用reset_index,可以重置索引,并将当前索引变成一个普通的列。
例如:
# 使用一个新的变量接收新设行索引后的数据框
df3 = gzmt.set_index('day')
# 使用日期值作为行索引获取指定日期的数据
df3.loc['2001/8/27']
STOCK_CODE 6.005191e+06
open 3.451000e+01
close 3.555000e+01
maximum 3.778000e+01
minimum 3.285000e+01
volume 4.063180e+05
TURNOVER 1.410347e+09
Name: 2001/8/27, dtype: float64
列索引
在 pandas 中,每个 DataFrame 都有一个列索引,它定义了列的标签。以下是一些常用的操作和概念:
- 查看列索引: 使用
df.columns 可以查看 DataFrame df 的所有列名。
- 选择列: 可以通过列名选择特定的列,例如
df['column_name']。
- 重命名列: 使用
df.rename(columns={'old_name': 'new_name'}) 可以重命名列。
- 设置列索引: 可以通过
df.set_index('column_name') 将某一列设置为索引。
- 重置列索引: 使用
df.reset_index() 可以重置索引,并将当前索引变成一个普通的列。
- 多级列索引: 在更复杂的 DataFrame 中,可以有多级列索引,这在处理分组、多维数据时非常有用。
Index(['day', 'STOCK_CODE', 'open', 'close', 'maximum', 'minimum', 'volume',
'TURNOVER'],
dtype='object')
0 35.55
1 36.86
2 36.86
3 36.38
4 37.10
...
4090 549.09
4091 524.00
4092 548.90
4093 563.00
4094 599.90
Name: close, Length: 4095, dtype: float64
使用loc属性按照标签获取DataFrame数据
loc 索引器的一般形式是 loc[*, *] ,其中第一个 * 代表行的选择,第二个 * 代表列的选择,如果省略第二个位置写作 loc[*] ,这个 * 是指行的筛选。其中, * 的位置一共有五类合法对象,分别是:单个元素、元素列表、元素切片、布尔列表以及函数。
在loc方法中使用单个元素获取数据
使用诸如loc['xxx']这样的方式,通过指定行索引的值,即可获得DataFrame中的指定行数据,在DataFrame中,单行或单列数据,都是以series的数据类型返回的。
如果只是要获取特定列的数据,则忽略行的参数即可,具体为loc[:,'列名']。
# 获取gzmt数据表中的第4行数据
gzmt.loc[3]
day 2001/8/29
STOCK_CODE 6005191
open 36.98
close 36.38
maximum 37.0
minimum 36.1
volume 53252
TURNOVER 194689000
Name: 3, dtype: object
# 获取gzmt数据表中的第4行数据中close变量的值
gzmt.loc[3,'close']
在loc方法使用元素列表获取多个数据
在loc方法中,传入由多个索引值组成的列表,即可获得指定的多行或多列的数据,注意要将索引值用列表的形式传入。
df3.loc[['2001/10/8','2002/10/8'],['open','close']]
| day |
|
|
| 2001/10/8 |
37.00 |
36.58 |
| 2002/10/8 |
28.15 |
28.08 |
在loc方法使用元素切片获取多个数据
元素切片也可作为loc方法的参数,或者某个范围内的数据。
df3.loc['2001/10/8':'2001/10/11']
| day |
|
|
|
|
|
|
|
| 2001/10/8 |
6005191 |
37.00 |
36.58 |
37.18 |
36.25 |
6552 |
24091000 |
| 2001/10/9 |
6005191 |
36.60 |
37.30 |
37.50 |
36.60 |
9558 |
35498000 |
| 2001/10/10 |
6005191 |
37.30 |
36.10 |
37.43 |
36.03 |
17548 |
63956000 |
| 2001/10/11 |
6005191 |
36.01 |
35.75 |
36.50 |
35.65 |
12306 |
44319000 |
在loc方法中使用布尔列表获取多个数据
使用布尔列表作为loc方法的参数,可以将列表中为真值的行取出来。布尔列表的长度要和DataFrame行数一致。布尔列表可以通过对变量的计算获得。
例如:
# 创建布尔列表,布尔列表的长度要和DataFrame行数一致
布尔列表 = [False] * 4095
布尔列表[1] = True
df3.loc[布尔列表]
| day |
|
|
|
|
|
|
|
| 2001/8/28 |
6005191 |
34.99 |
36.86 |
37.0 |
34.61 |
129647 |
463463008 |
# 使用条件表达式构造布尔列表
条件1 = df3.open < 35
条件2 = df3.close < 35
筛选条件 = 条件1 & 条件2
df3.loc[筛选条件].head(3)
| day |
|
|
|
|
|
|
|
| 2001/10/17 |
6005191 |
34.79 |
34.20 |
34.81 |
33.90 |
12507 |
42766000 |
| 2001/10/18 |
6005191 |
34.20 |
34.04 |
34.66 |
33.91 |
4983 |
16999000 |
| 2001/10/19 |
6005191 |
34.00 |
33.50 |
34.15 |
33.01 |
15687 |
52422000 |
在loc方法中使用函数索引数据
在 pandas 的 loc 方法中使用函数来索引数据,它可以让你根据复杂的条件或逻辑来选择数据。这通常通过将一个函数传递给 loc 来实现,该函数应用于 DataFrame 并返回布尔值。
这里的函数,必须以前面的四种合法形式之一(单个元素、元素列表、元素切片、布尔列表)为返回值,并且函数的输入值为 DataFrame 本身。
# 使用函数作为索引方式
def 筛选函数(df):
条件1 = df.open < 35
条件2 = df.close < 35
筛选条件 = 条件1 & 条件2
return 筛选条件
df3.loc[筛选函数].head(3)
| day |
|
|
|
|
|
|
|
| 2001/10/17 |
6005191 |
34.79 |
34.20 |
34.81 |
33.90 |
12507 |
42766000 |
| 2001/10/18 |
6005191 |
34.20 |
34.04 |
34.66 |
33.91 |
4983 |
16999000 |
| 2001/10/19 |
6005191 |
34.00 |
33.50 |
34.15 |
33.01 |
15687 |
52422000 |
使用iloc属性按照位置获取DataFrame数据
使用iloc方法获取数据的方法,与loc类似,可以接受单个元素、元素列表、元素切片、布尔列表以及函数。与loc方法的区别是,iloc的值是整数,而loc方法的值是标签值(取决于index的值类型)
更简洁的查询方法query
query() 方法是 pandas 提供的一种强大且便捷的方式,用于根据指定的查询字符串来筛选 DataFrame 中的数据。这个方法允许你使用类似 SQL 的语法来选择满足特定条件的行,使得代码更简洁易读,尤其是在处理复杂条件时。
基本用法
基本的 query() 用法涉及将一个条件表达式作为字符串传递给这个方法。例如:
import pandas as pd
df = pd.DataFrame({
'A': [1, 2, 3, 4],
'B': [5, 6, 7, 8]
})
result = df.query('A > 2')
这里,df.query('A > 2') 会选择所有 A 列中值大于 2 的行。
复杂条件
你也可以在 query() 方法中使用更复杂的条件,包括逻辑运算符(如 and, or, not):
result = df.query('A > 2 and B < 8')
这会选择 A 大于 2 且 B 小于 8 的所有行。
使用变量
如果你想在查询字符串中使用外部变量的值,可以通过在变量名前加 @ 符号来实现:
threshold = 2
result = df.query('A > @threshold')
索引查询
query() 也可以用于查询索引:
df.index.name = 'index'
result = df.query('index > 1')
这里,我们首先给索引命名(这是使用 query() 查询索引的一个要求),然后选择索引大于 1 的行。
query() 方法是一个非常有用的工具,它可以简化选择和过滤 DataFrame 行的操作。通过允许你使用类似于自然语言的查询字符串,它使代码更加清晰和直观。不过,需要注意的是,由于 query() 方法使用字符串来传达指令,它可能比传统的布尔索引方式在性能上略有不足,尤其是在处理非常大的数据集时。
df3.query('open < 35 and close < 35').head(3)
| day |
|
|
|
|
|
|
|
| 2001/10/17 |
6005191 |
34.79 |
34.20 |
34.81 |
33.90 |
12507 |
42766000 |
| 2001/10/18 |
6005191 |
34.20 |
34.04 |
34.66 |
33.91 |
4983 |
16999000 |
| 2001/10/19 |
6005191 |
34.00 |
33.50 |
34.15 |
33.01 |
15687 |
52422000 |
DataFrame中的常用函数
info函数
info函数打印出数据框的概要信息,如行索引、列变量个数、列变量类型、非空值个数等等。注意:DataFrame还有个info属性,不要混淆。
describe函数
describe函数将输出数据框中数值列的主要统计量,如均值、最大值、最小值等等。对于类型变量,则输出类型的个数,最多的类型及次数等信息。
常用描述统计函数
sum |
总和 |
mean |
均值 |
median |
中位值 |
var |
方差 |
std |
标准差 |
max |
最大值 |
min |
最小值 |
count |
非缺失值个数 |
idxmax |
最大值对应的索引 |
cumsum |
累积和 |
唯一值函数
unique函数与nunique函数分别获得指定变量其唯一值组成的列表和唯一值的个数。nunique函数不会统计空值。value_counts 可以得到唯一值和其对应出现的频数。drop_duplicates返回去除重复值的所有数据。默认情况为按照所有列进行对比,也可以按照指定列。
值替换函数
where 函数在传入条件为 False 的对应行进行替换,而 mask 在传入条件为 True 的对应行进行替换,当不指定替换值时,替换为缺失值。replace 函数可以通过字典构造,或者传入两个列表来进行替换。
排序函数
sort_values可以按照单列或多列进行升序、降序排序。
自定义功能函数
apply函数的功能是将一个自定义函数作用于DataFrame的行或者列上,是后续数据清理和数据变量计算时常用的函数。applymap函数可以认为是apply()函数的扩展,其功能是将自定义函数作用于DataFrame的所有元素 。
复制函数
copy函数复制一份数据框,在一些情境下,当我们需要做一些不改变原数据框的操作时,可以用copy函数生成一个新的数据框。
删除行或列
drop函数可以按照行或列删除数据。该函数的主要参数有index,index表示需要删除行的序号,index的值可以是列表,也可以是单个的值。参数columns表示需要删除的列名称,其值可以是列表,也可以是单个的值。
在数据框中进行抽样
sample 函数中的主要参数为 n,axis,frac,replace,weights ,前三个分别是指抽样数量、抽样的方向(0为行、1为列)和抽样比例(0.3则为从总体中抽出30%的样本)。replace 和weights 分别是指是否放回和每个样本的抽样相对概率,当 replace=True 则表示有放回抽样。
DataFrame的分组
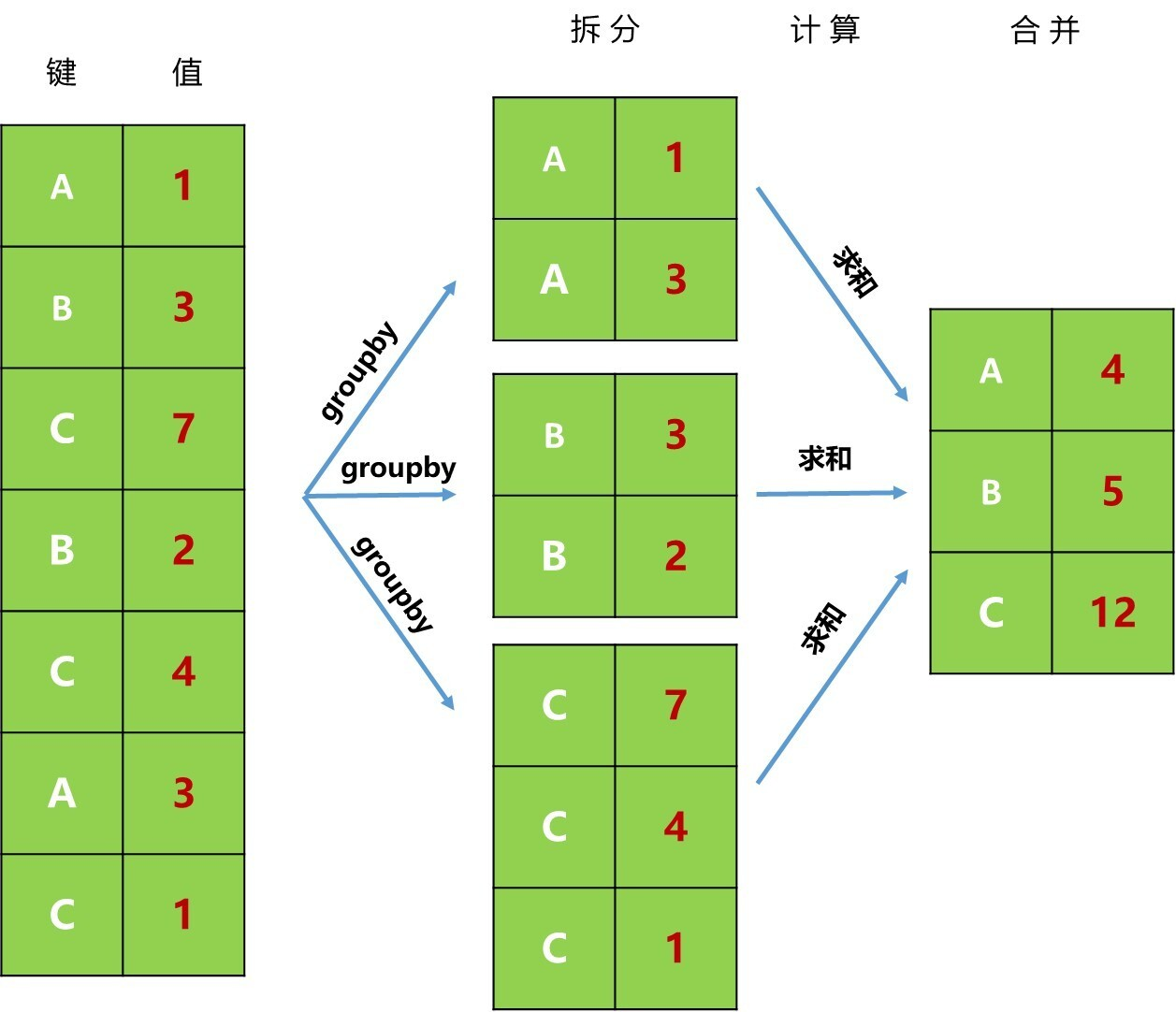
groupby函数让你可以在一条语句中顺利实现数据分组以及组内预统两者统一,并且你可以自定义预统函数,因此语法功能非常强大。有了groupby功能,让我们操作数据及更加得心应手,更加精细化。
分组操作的要素
分组操作,必须明确三个要素:分组依据、数据来源、操作及其返回结果。
例如:
df = pd.DataFrame({
"name": ["A", "B", "C", "B", "C", "A", "C"],
"value": [1, 3, 7, 2, 4, 3, 1]
})
# 以`df.groupby("name")["value"].sum()`为例,分组依据为`name`,数据来源为`vaule`,操作为`sum`。
df.groupby("name")["value"].sum()
name
A 4
B 5
C 12
Name: value, dtype: int64
groupby和分组运算过程详解
groupby拆分过程:根据提供的数据集的一个或多个键,把数据集按照某一方向拆分为多组。比如df.groupby("name")["value"].sum()就是以name列为键(在例子中有A、B、C三个值),在行上进行拆分(方向为axis=0),分成A、B、C三组。- 计算:在每一个分组上对值进行计算,并得到一个新值。如
df.groupby("name")["value"].sum()中就是对值进行求和运算。
- 合并:把每个分组上计算的结果进行合并(
concat运算),返回最终的结果。df.groupby("name")["value"].sum()最终返回系列类型的数据。
分组依据
分组依据除了单个列名外,还可以是多个列名,也可是基于列中元素的逻辑表达式。例如:
# 构造分组条件
condition = df.value > df.value.mean()
# 以布尔表达式为分组套件,计算满足条件的value的平均值
df.groupby(condition)['value'].sum()
value
False 10
True 11
Name: value, dtype: int64
内置分组计算函数
pandas内置了一些常见计算函数:
| sum |
非NA值的和 |
| mean |
非NA值的平均值 |
| median |
非NA值的中位数 |
| std,var |
无偏标准差和方法 |
| min,max |
非NA值的最大和最小值 |
| prod |
非NA值的积 |
| fist,last |
第一个、最后一个非NA值 |
| count |
分组中非NA值的数量 |
| size |
分组的大小 |
自定义计算函数apply()
apply方法会将每个分组的数据结果代入传入的函数,再把各个分组的结果合并到一起。